

Est-il possible, à partir des œuvres de plusieurs écrivains, de retrouver les courants de pensées ou les genres littéraires auxquels ils appartiennent ? Dit autrement, peut-on regrouper les auteurs qui s’intéressent aux mêmes sujets, aux mêmes thématiques ? Une possibilité est bien sûr de faire ce que l’on a appris en cours de français et de lire l’ensemble des œuvres littéraires avant de les comparer pour faire ressortir des groupes d’auteurs d’un même courant ou d’un même genre. Mais comment faire si l’on doit trier 18 auteurs à partir de leurs 317 œuvres ?
Et si l’on faisait appel aux mathématiques ou plus exactement à la statistique? Au premier abord, on peut se demander ce que vient faire la statistique ici puisque l’on ne dispose que des auteurs et de leurs œuvres littéraires, et donc pas du moindre nombre!
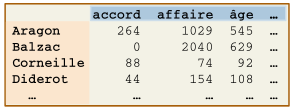
Cependant, grâce à des logiciels et aux œuvres au format numérique, on peut compter, pour chaque auteur, le nombre d’occurrences de chaque mot de la langue française. On obtient ainsi un tableau croisant les auteurs et les mots (et dans une case le nombre de fois où tel mot est employé par tel auteur). L’idée est alors de considérer que les auteurs qui emploient les mêmes mots dans des proportions similaires s’intéressent aux mêmes sujets et ont les mêmes préoccupations.
À partir de ce principe simple et du tableau ci-dessus, la statistique propose une méthode de visualisation des données pour faire l’analyse textuelle. Les auteurs sont alors positionnés sur un plan (cf. figure ci-dessous) de sorte que deux auteurs qui emploient globalement les mots dans des proportions équivalentes sont proches tandis qu’ils sont éloignés si au contraire ils emploient des mots très différents.
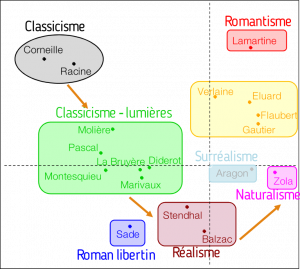
Ainsi Corneille et Racine sont proches et ils sont très différents (car très éloignés) de Zola. En effet, Corneille et Racine sont deux auteurs particulièrement classiques du XVIIe tandis que Zola est un naturaliste du XIXe. Stendhal et Balzac, des réalistes, sont très éloignés de Lamartine qui est un romantique. On retrouve ici que les auteurs réalistes ont un point commun : s’éloigner des excès romantiques ! On détecte ainsi une évolution du vocabulaire choisi selon les auteurs, mais aussi selon les siècles et les courants littéraires.
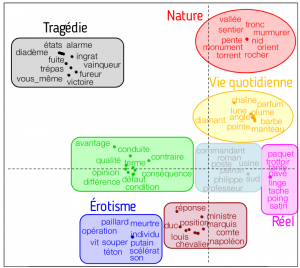
Une fois les auteurs placés, aidons-nous des mots qu’ils emploient plus fréquemment que les autres auteurs pour connaître leurs sujets de prédilection. Les mots peuvent être placés sur le même plan que les auteurs, mais par souci de lisibilité, ils sont ici reproduits sur un nouveau plan. Le code couleur utilisé est le même dans les deux plans, ainsi on peut voir que Corneille et Racine sur-emploient des mots comme états, alarme, ingrat, vainqueur, victoire, qui sont des mots relatifs aux tragédies qu’ils écrivent. Zola est quant à lui ancré dans le réel puisqu’il utilise des mots comme linge, poing, satin, trottoir. Lamartine, le romantique, utilise beaucoup de termes évoquant la nature : vallée, roc, sentier, rocher, torrent, etc. On retrouve ainsi les particularités des thèmes qui caractérisent chaque courant.
Notons bien que l’analyse réalisée ci-dessus est automatique et que les plans sont construits uniquement à partir du tableau d’occurrences, sans utiliser à aucun moment le sens des mots. Ainsi, on aurait pu aussi facilement travailler sur des œuvres littéraires allemandes et comparer les œuvres de Goethe, Kant, Nietzsche et autres… sans avoir jamais appris le moindre mot d’allemand !
La technique présentée ici permet au linguiste d’aborder des corpus de textes importants, mais elle peut aussi lui permettre d’analyser une œuvre, par exemple chapitre par chapitre ou encore personnage par personnage. C’est donc un outil avant, bien sûr, de regarder plus en détail l’analyse pour approfondir l’étude.
Post-scriptum
Ce texte appartient au dossier thématique « Maths et langage ».
ÉCRIT PAR

François Husson
Professeur de statistique - Agrocampus Ouest (Rennes)
9h28
Bonjour,
Je serais curieux de savoir comment placer les auteurs et mots dans le plan. Est-ce que c’est facile à expliquer ? Est-ce que ce plan a un nom mathématique ?
7h18
Il me semble qu’il s’agit d’une Analyse en Composante Principale. Selon ce principe chaque auteur est représenté dans un espace de de dimension N, les coordonées de chaque auteur dans cet espace sont le nombre d’occurence pour le mot n1, n2 … nN.
A partir du nuage de point qu’on obtient on cherche deux vecteurs qui représentent au mieux ce nuage de point. (là c’est technique). Ces deux vecteurs servent ensuite à former le plan.
18h47
Bonjour
En fait il s’agit d’une analyse factorielle des correspondance (AFC). Le principe est proche de l’analyse en composantes principales mais ce n’est pas équivalent, et c’est tout à doit adapté à l’analyse textuelle.
Si vous voulez en savoir plus sur ces méthodes vous trouverez ici des vidéos de cours décrivant acp Afc et autres méthodes.
http://math.agrocampus-ouest.fr/infoglueDeliverLive/membres/Francois.Husson/enseignement#AnaDo
Bonne visualisation
FH